如何选择正确的数据采集方式,从而使你的数据分析更加精准!
作者:探码科技, 原文链接: http://www.tanmer.com/web-bigdata/545
数据分析是指用适当的统计分析方法对收集来的大量数据进行分析,提取有用信息和形成结论而对数据加以详细研究和概括总结的过程。数据分析使我们的决策更加的科学性!
然而现在很多数据分析中存在普遍的问题:存在很多低质量的数据最后导致数据分析结果较低,正如前美国首席数据科学家DJ Patil所说:“不过分的说:任何数据项目中80%的工作都在采集清理数据。”如果无法采集高质量的数据资源,再先进的分析算法都是白搭。
探码科技作为成都本土的Daas(数据及服务)公司致力帮助企业实现数据资产化运营。我们为您提供干净,结构化和有组织的web数据,以便您的数据分析尽可能准确。但与此同时,我们希望给您传输一些web数据采集的一些知识,避免您在数据采集过程中产生低质量的数据。
爬虫采集的方法
我们绝大多数人每天都使用网络 - 用于新闻,购物,社交以及您可以想象的任何类型的活动。但是,当从网络上获取数据用于分析或研究目的时,则需要以更技术性的方式查看Web内容 - 将其拆分为由其组成的构建块,然后将它们重新组合为结构化的,机器可读数据集。通常文本Web内容转换为数据分为以下三个基本步骤 :
爬虫
Web爬虫是一种自动访问网页的脚本或机器人,其作用是从网页抓取原始数据 - 最终用户在屏幕上看到的各种元素(字符、图片)。 其工作就像是在网页上进行ctrl + a(全选内容),ctrl + c(复制内容),ctrl + v(粘贴内容)按钮的机器人(当然实质上不是那么简单)。
通常情况下,爬虫不会停留在一个网页上,而是根据某些预定逻辑在停止之前抓取一系列网址 。 例如,它可能会跟踪它找到的每个链接,然后抓取该网站。当然在这个过程中,需要优先考虑您抓取的网站数量,以及您可以投入到任务中的资源量(存储,处理,带宽等)。
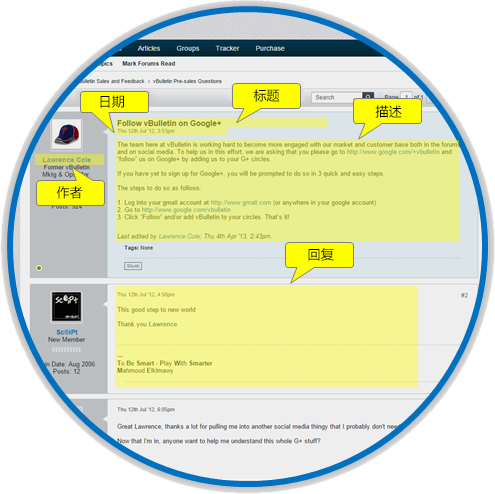
解析
解析意味着从数据集或文本块中提取相关信息组件,以便以后可以容易地访问它们并将其用于其他操作。要将网页转换为实际上对研究或分析有用的数据,我们需要以一种使数据易于根据定义的参数集进行搜索,分类和服务的方式进行解析。
存储和检索
最后,在获得所需的数据并将其分解为有用的组件之后,通过可扩展的方法来将所有提取和解析的数据存储在数据库或集群中,然后创建一个允许用户可及时查找相关数据集或提取的功能。
当我们已经了解到爬虫采集的方法后,我们要开始考虑可用于获取所需数据的各种工具与技术了。数据的爬虫采集的工具大致为以下三种;
DIY(定制)
第一种编写自己的网络爬虫,抓取您需要的任何数据并根据需要随时运行(这种需要您的公司有了解爬虫技术的人才)。
这种方法的主要优点是具备高灵活性和可定制性:可以准确定义要获取的数据,频率以及您希望如何解析自己数据库中的数据。
这使您可以根据您的计划的确切范围定制Web采集方案、适合爬取一组非常特定的网站(范围相对较小)。
然而,定制的爬行抓取并非没有缺点,特别是涉及更复杂的项目时。比如您希望了解大量网站中的更广泛的趋势,DIY爬行变得更加复杂 - 需要在计算资源和开发时间方面进行更多投入。
用于临时分析的抓取工具
另一种常用技术是购买商业抓取工具,抓取工具消除了DIY方法的一些复杂性,但是,它们仍然最适合于特定项目 - 即在特定时间间隔内抓取特定网站。
如果您正在寻求设置更大规模的操作,其中重点不在于自定义解析,而在于开放式Web的全面覆盖,抓取工具就不太合适,因为频繁的数据刷新率以及对大量数据集的轻松访问,会遇到以下几种问题:
- 根据定义,网络抓取工具只从您“指向”它们的任何网站获取数据。如果您不确切地知道提前查看的位置,则可能会错过重要数据 - 例如,在媒体监控用例中,您不了解可能提及您的客户的所有可能的出版物。
- 高级抓取工具是为自定义提取而构建的,并且在识别和解析数据以用于分析用途方面通常具有非常高级的功能。然而,这通常体现在基于所抓取取的网站数量的定价模型中 - 导致较大项目的成本膨胀。
- 开发人员开销仍然以管理已爬网站点列表和维护抓取工具的形式存在。
- 由于在激活抓取工具之前未收集数据,因此您将无法访问历史数据。
商用抓取工具为临时项目提供了较好的技术支持,提供了从特定网站获取和解析数据的高度复杂方法。但是,在为万维网构建全面的数据采集解决方案时,它们的可扩展性和可行性较低;这时你就需要更加强大的“数据抓取服务”。
DaaS服务商提供的Web服务
第三种你将不需要进行数据爬取和分析的工作,由专业的数据服务(DaaS)提供商为你全权负责。在此模型中,您将获取由DaaS提供商提取的清晰,结构化和有组织的数据,使您能够跳过构建或购买自己的提取基础架构的整个过程,并专注于您正在开发的分析,研究或产品。
但是,对于大型操作,Web数据即服务在规模和易于开发方面提供了几个独特的优势:
- 与专业提供商合作可以让您利用一流的爬虫和抓取技术,而不是让您自己的开发人员尝试重新开发爬虫工具(费时费钱)。
- 可靠的Web DaaS提供商提供全面数据爬取覆盖,使您能够立即访问来自Web上任何相关来源的数据。智能索引和抓取功能使数据在网络上传播时自动添加新来源,而不是等待您指令爬取新数据。
- 通过API调用可以轻松访问结构化数据,从而简化了集成。
- 按需使用数据的能力使您可以更灵活地启动和扩展数据驱动的操作,而无需进行任何大量的前期投资。
- 访问全面的网络覆盖,无需维护自己的网站列表进行抓取。
这些优势使Web数据及服务-成为媒体监控,财务分析,网络安全,文本分析以及需要快速访问更新频繁数据源的最佳解决方案。

除了更多结构化数据的提供之外,我们还为企业和组织提供更多另类数据,以应用预测分析,从而使您做出更明智的投资决策。