什么是机器学习?
作者:探码科技, 原文链接: http://www.tanmer.com/learning/310
机器学习定义:
机器学习(Machine Learning, ML)是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。
机器学习是指用某些算法指导计算机利用已知数据得出适当的模型,并利用此模型对新的情境给出判断的过程。 由此看来,机器学习的思想并不复杂,它仅仅是对人类生活中学习过程的一个模拟。 而在这整个过程中,最关键的是数据,是数据,是数据!重要的事情说三遍。
机器学习是人工智能的一个分支,目标是赋予机器一种新的能力。 机器学习有很多定义,广为人知的有如下两条:“机器学习是对能通过经验自动改进的计算机算法的研究” 机器学习是用数据或以往的经验,以此优化计算机程序的性能标准。机器学习是人工智能的核心,并且十分广泛的应用,例如:数据挖掘、计算机视觉、自然语言处理、生物特征识别、搜索引擎、医学诊断、检测信用卡欺诈、证券市场分析、DNA序列测序、语音和手写识别、战略游戏和机器人运用。
机器学习在生活中的例子:
- 垃圾邮件检测:根据邮箱中的邮件,识别哪些是垃圾邮件,哪些不是。这样的模型,可以程序帮助归类垃圾邮件和非垃圾邮件。这个例子,我们应该都不陌生。
- 信用卡欺诈检测:根据用户一个月内的信用卡交易,识别哪些交易是该用户操作的,哪些不是。这样的决策模型,可以帮助程序退还那些欺诈交易。
- 数字识别:根据信封上手写的邮编,识别出每一个手写字符所代表的数字。这样的模型,可以帮助程序阅读和理解手写邮编,并根据地利位置分类信件。
- 股票交易:根据一支股票现有的和以往的价格波动,判断这支股票是该建仓、持仓还是减仓。这样的决策模型,可以帮助程序为金融分析提供支持。
- 客户细分:根据用户在试用期的的行为模式和所有用户过去的行为,识别出哪些用户会转变成该产品的付款用户,哪些不会。这样的决策模型,可以帮助程序进行用户干预,以说服用户早些付款使用或更好的参与产品试用。
机器学习形式的分类
1、有监督学习(Supervised learning):通过生成一个函数将输入映射为一个合适的输出(通常也称为标记,多数情况下训练集都是有人工专家标注生成的)。例如分类问题,分类器更加输入向量和输出的分类标记模拟了一个函数,对于新的输入向量,得到它的分类结果。
监督学习(就像一个学生通过做多套高考模拟卷并订正答案的方式来提高高考成绩。在这种情形下,数据就像是监督计算机进行学习的教师,故而得名。)
2、无监督学习(Unsupervised learning):与有监督学习相比,训练集没有人为标注的结果。常见的无监督学习算法有聚类。(这就像做了好多套没有答案的模拟卷,最后还要去高考,听上去很恐怖但是可以根据所做的题收货价值,比方说哪些题出现频率高,那些题爱扎堆考,等等。无监督学习希望从数据中挖掘的正是这一类信息,常见的例子有聚类,关联规则挖掘,离群点检测等等。)
3、半监督学习: 介于监督学习与无监督学习之间。
4、强化学习(Reinforcement learning): 通过观察来学习如何做出动作,每个动作都会对环境有所影响,而环境的反馈又可以引导该学习算法。
监督学习又分:回归/分类
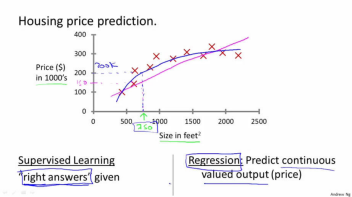
在回归问题中,我们会预测一个连续值。也就是说我们试图将输入变量和输出用一个连续函数对应起来;而在分类问题中,我们会预测一个离散值,我们试图将输入变量与离散的类别对应起来。
通过房地产市场的数据,预测一个给定面积的房屋的价格就是一个回归问题。这里我们可以把价格看成是面积的函数,它是一个连续的输出值。 但是,当把上面的问题改为“预测一个给定面积的房屋的价格是否比一个特定的价格高或者低”的时候,这就变成了一个分类问题, 因为此时的输出是‘高’或者‘低’两个离散的值。
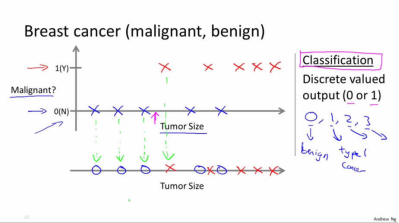
给定医学数据,通过肿瘤的大小来预测该肿瘤是恶性瘤还是良性瘤(课程中给的是乳腺癌的例子),这就是一个分类问题,它的输出是0或者1两个离散的值。(0代表良性,1代表恶性)。
分类问题的输出可以多于两个,比如在该例子中可以有{0,1,2,3}四种输出,分别对应{良性, 第一类肿瘤, 第二类肿瘤, 第三类肿瘤}。
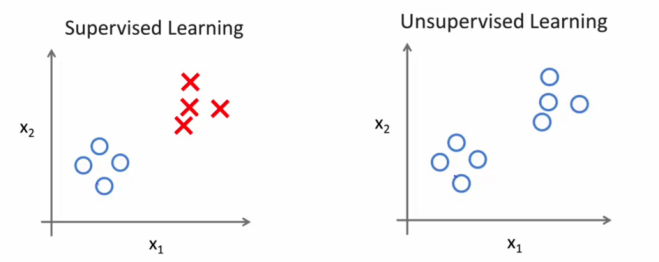
下图中上下两个图只是两种画法。第一个是有两个轴,Y轴表示是否是恶性瘤,X轴表示瘤的大小; 第二个是只用一个轴,但是用了不同的标记,用O表示良性瘤,X表示恶性瘤。
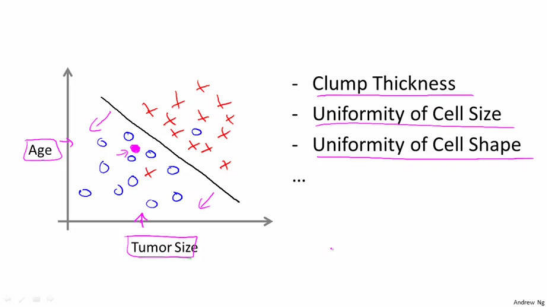
在这个例子中特征只有一个,那就是瘤的大小。 有时候也有两个或者多个特征, 例如下图, 有“年龄”和“肿瘤大小”两个特征。(还可以有其他许多特征,如下图所示)
在无监督学习中,我们基本上不知道结果会是什么样子,但我们可以通过聚类的方式从数据中提取一个特殊的结构。在无监督学习中给定的数据是和监督学习中给定的数据是不一样的。在无监督学习中给定的数据没有任何标签或者说只有同一种标签。如下图所示: