用机器学习给企业打分的技术原理
作者:探码科技, 原文链接: http://www.tanmer.com/tech-blog/507
机器学习打分原理:
1. 数据分析
通过图形对之前打分系统的结果进行观察分析,了解数据的分布状态,确定样本数据的每个特征是否适合模型训练,并且通过图形确定数据是否线性或非线性,找到边界经验值。
2. 数据预处理
https://scikit-learn.org/stable/modules/preprocessing.html#preprocessing
企业的特征数据有很多,数据类型包含字符型,数值型和布尔型,需要把数据标准化之后,才能提供给下一步,进行模型训练。
数据集的标准化是scikit-learn中实现的许多机器学习估算器的常见要求 ; 如果单个特征看起来不像标准的正态分布数据,它们可能表现得很糟糕:具有零均值和单位方差的高斯分布。在实践中,我们经常忽略分布的形状,只是通过去除每个特征的平均值来转换数据以使其居中,然后通过将非常数特征除以它们的标准偏差来对其进行缩放。
处理方式包括:
1. 数据标准化
1. 编码分类特征(字符型)https://scikit-learn.org/stable/modules/preprocessing.html#encoding-categorical-features
2. K谱线离散化(数字型)https://scikit-learn.org/stable/modules/preprocessing.html#k-bins-discretization
2. 数据补全
https://scikit-learn.org/stable/modules/impute.html#impute
由于各种原因,许多企业数据集包含缺失值,通常编码为空格,NaN或其他占位符。然而,这样的数据集与scikit-learn估计器不兼容,这些估计器假设数组中的所有值都是数字的,并且所有数据都具有并保持含义。使用不完整数据集的基本策略是丢弃包含缺失值的整个行和/或列。然而,这是以丢失可能有价值的数据(即使不完整)为代价的。更好的策略是估算缺失值,即从数据的已知部分推断它们。有关插补的信息,请参阅常用术语和API元素词汇表。 数据补全有以下2个方法:
1. 均值补全
2. 标注值补全
3. 数据调整
1. 调整特征到一个范围 https://scikit-learn.org/stable/modules/preprocessing.html#scaling-features-to-a-range
另一种标准化是将特征缩放到给定的最小值和最大值之间,通常在0和1之间,或者使每个特征的最大绝对值按比例缩放到单位大小。这可以分别使用MinMaxScaler或实现MaxAbsScaler。使用此缩放的动机包括对特征的非常小的标准偏差的容错性以及在稀疏数据中保留零条目。
2. 调整稀疏数据 https://scikit-learn.org/stable/modules/preprocessing.html#scaling-sparse-data
将稀疏数据居中会破坏数据中的稀疏结构,因此很少是明智之举。但是,缩放稀疏输入是有意义的,尤其是在特征不同的情况下。
MaxAbsScaler 并且maxabs_scale专门用于扩展稀疏数据,是推荐的解决方案。但是, 只要显式传递给构造函数,scale并且StandardScaler可以接受scipy.sparse矩阵作为输入with_mean=False。否则ValueError会产生一个静音中心会破坏稀疏性并且通常会无意中分配过多的内存而导致执行崩溃。 RobustScaler不能适应稀疏输入,但您可以transform在稀疏输入上使用该方法。
请注意,缩放器接受Compressed Sparse Rows和Compressed Sparse Columns格式(请参阅scipy.sparse.csr_matrix和 scipy.sparse.csc_matrix)。任何其他稀疏输入将转换为Compressed Sparse Rows表示。为避免不必要的内存复制,建议在上游选择CSR或CSC表示。
最后,如果预期中心数据足够小,则使用toarray稀疏矩阵的方法显式地将输入转换为数组是另一种选择。
3. 模型选择
通过场景分析,确定模型方向 https://scikit-learn.org/stable/tutorial/machine_learning_map/index.html
解决机器学习问题最困难的部分通常是为项目找到正确的估算器。不同的估计器更适合于不同类型的数据和不同的问题,下面的流程图旨在为用户提供一些粗略的指导,说明如何处理有关尝试数据的估算器的问题。
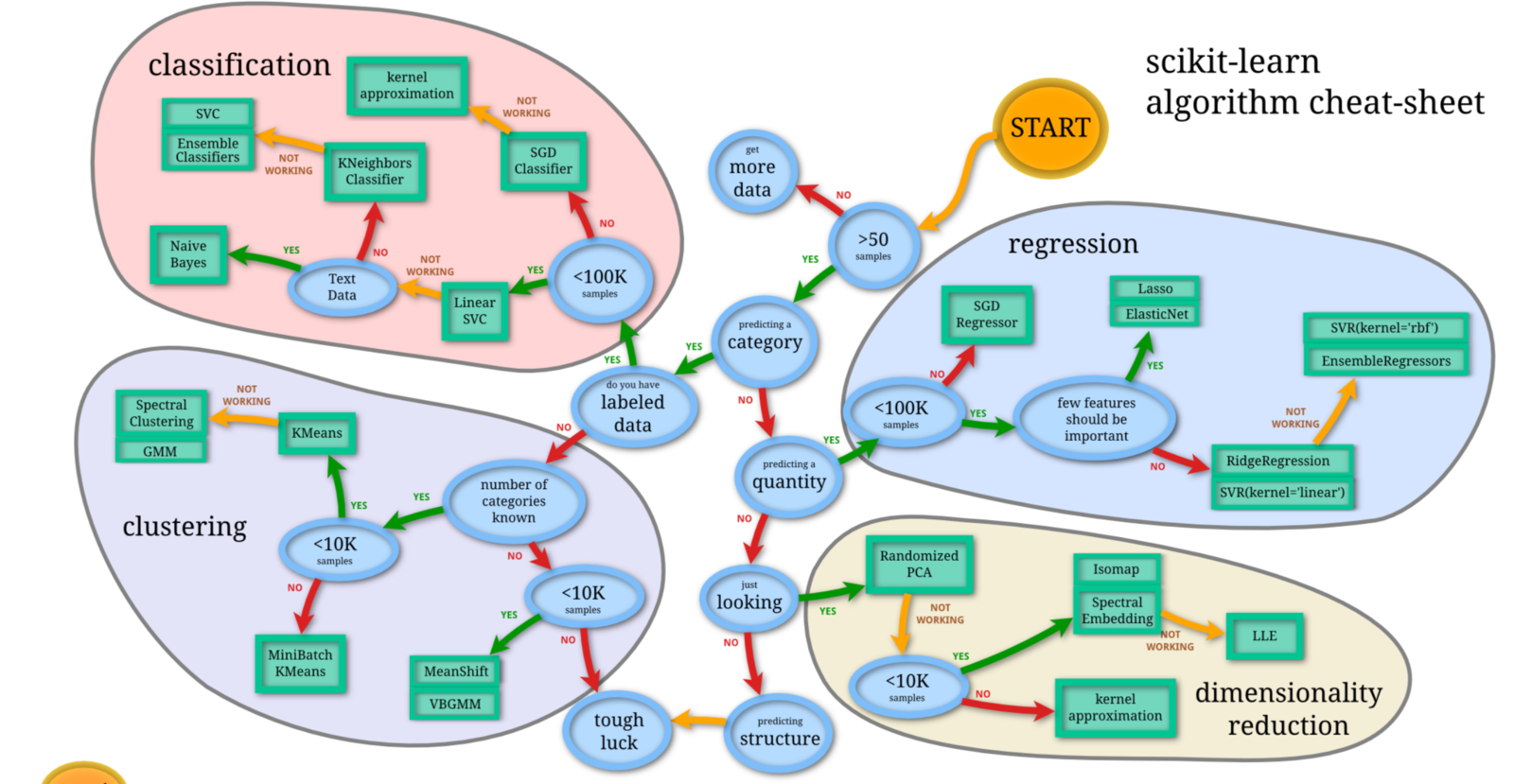
通过我们对企业数据的初步分析,可选择 SVM 支持向量机建模 和 NNR 神经网络回归建模。
支持向量分类的方法可以扩展到解决回归问题。此方法称为支持向量回归。由支持向量分类(如上所述)产生的模型仅取决于训练数据的子集,因为用于构建模型的成本函数不关心超出边界的训练点。类似地,由支持向量回归产生的模型仅取决于训练数据的子集,因为用于构建模型的成本函数忽略了接近模型预测的任何训练数据。
https://scikit-learn.org/stable/modules/svm.html#regression
通过神经网络,对不同场景的数据自动识别出模型 https://scikit-learn.org/stable/auto_examples/neural_networks/plot_mlp_alpha.html#sphx-glr-auto-examples-neural-networks-plot-mlp-alpha-py
通过全面网格搜索和交叉验证,自动找出算法模型,自动优化参数,免去人工干预。
自动GridSearch 自动选择模型 SVR 和 KRR 参数的实例: https://scikit-learn.org/stable/auto_examples/plot_kernel_ridge_regression.html#sphx-glr-auto-examples-plot-kernel-ridge-regression-py
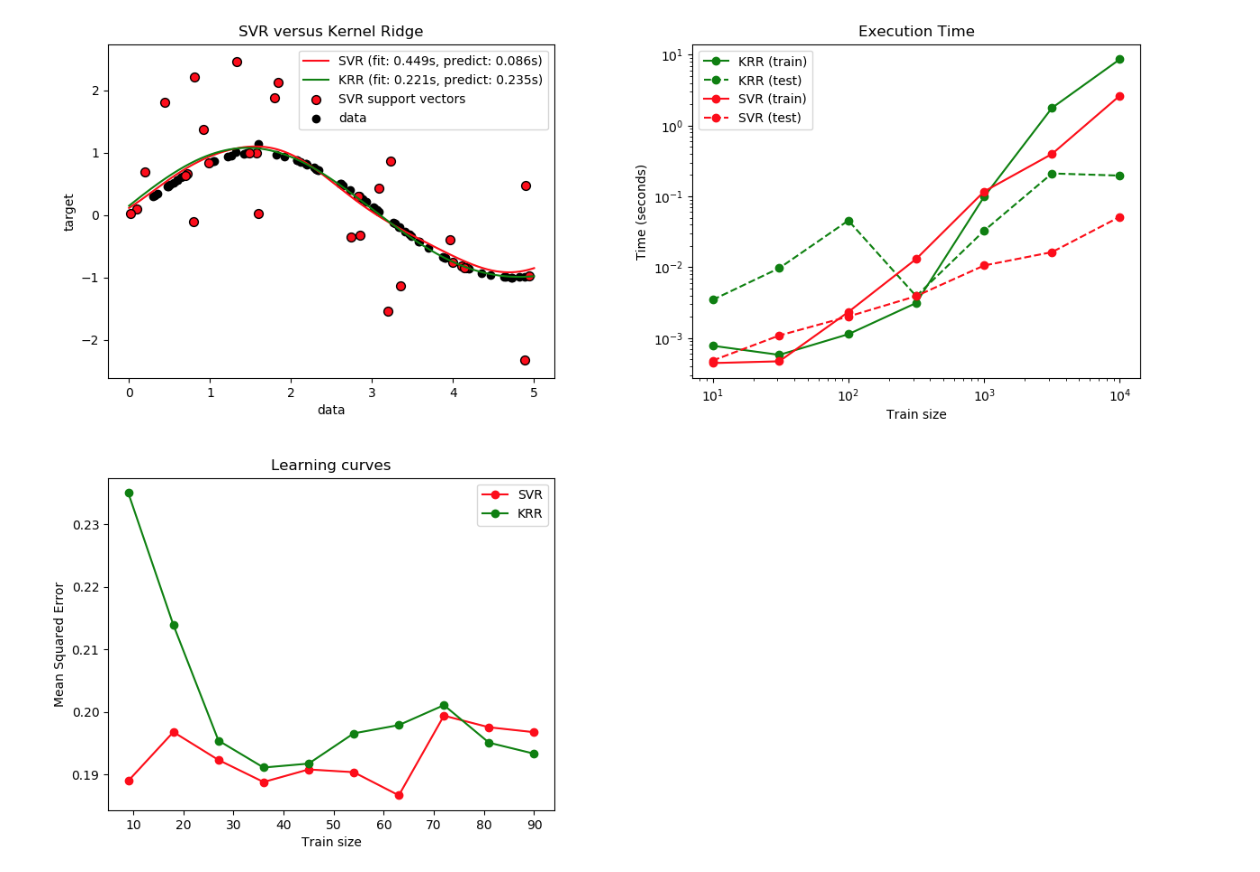
4. 模型训练
基于自动模型选择系统,可在每个周期内,基于新旧数据自动训练并优化模型,实现真正的人工智能