为什么越来越多的企业开始应用机器学习
作者:探码科技, 原文链接: http://www.tanmer.com/learning/317
前言:机器学习是近20多年兴起的一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、计算复杂性理论等多门学科。机器学习理论主要是设计和分析一些让计算机可以自动“学习”的算法。机器学习算法是一类从数据中自动分析获得规律,并利用规律对未知数据进行预测的算法。因为学习算法中涉及了大量的统计学理论,机器学习与推断统计学联系尤为密切,也被称为统计学习理论。算法设计方面,机器学习理论关注可以实现的,行之有效的学习算法。很多推论问题属于无程序可循难度,所以部分的机器学习研究是开发容易处理的近似算法。
机器学习已广泛应用于数据挖掘、计算机视觉、自然语言处理、生物特征识别、搜索引擎、医学诊断、检测信用卡欺诈、证券市场分析、DNA序列测序、语音和手写识别、战略游戏和机器人等领域。
一、机器学习的定义
机器学习有一下几种定义:
- 机器学习是一门人工智能的科学,该领域的主要研究对象是人工智能,特别是如何在经验学习中改善具体算法的性能。
- 机器学习是对能通过经验自动改进的计算机算法的研究。
- 机器学习是用数据或以往的经验,以此优化计算机程序的性能标准。
二、机器学习分类
机器学习可以分成下面几种类别:
- 监督学习从给定的训练数据集中学习出一个函数,当新的数据到来时,可以根据这个函数预测结果。监督学习的训练集要求是包括输入和输出,也可以说是特征和目标。训练集中的目标是由人标注的。常见的监督学习算法包括回归分析和统计分类。
- 无监督学习与监督学习相比,训练集没有人为标注的结果。常见的无监督学习算法有聚类。
- 半监督学习介于监督学习与无监督学习之间。
- 增强学习通过观察来学习做成如何的动作。每个动作都会对环境有所影响,学习对象根据观察到的周围环境的反馈来做出判断。
监督学习和非监督学习的差别就是训练集目标是否人标注。他们都有训练集 且都有输入和输出
三、机器学习算法列表
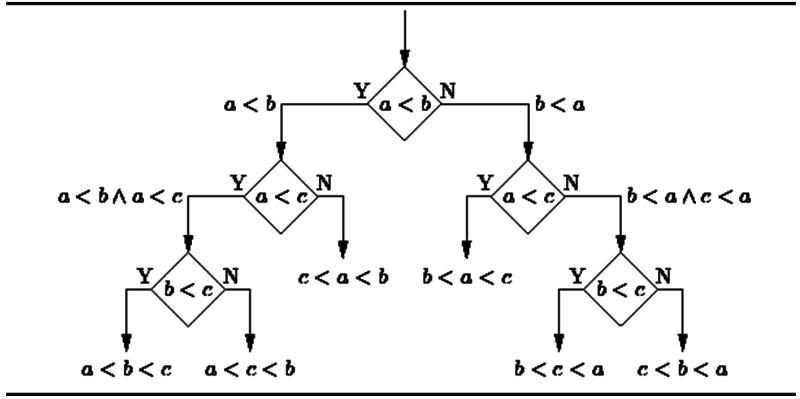
- 决策树(Decision tree)
决策树是一个决策支持工具,它使用树形图或者决策模型以及可能性序列,包括偶然事件的结果、资源成本和效用。下图是其基本原理:
- 朴素贝叶斯分类(Naive Bayesian classification)
朴素贝叶斯分类器是一类简单的概率分类器,它基于贝叶斯定理和特征间的强大的(朴素的)独立假设。图中是贝叶斯公式,其中P(A|B)是后验概率,P(B|A)是似然,P(A)是类先验概率,P(B)是预测先验概率。

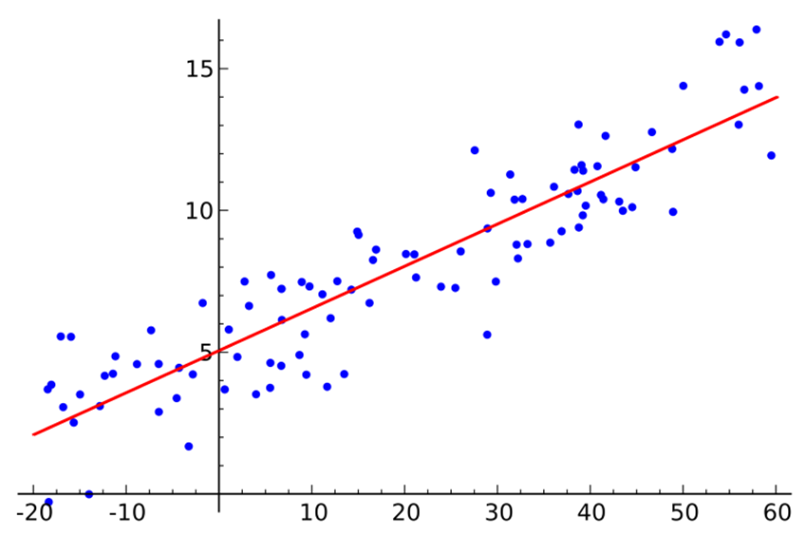
- 最小二乘法(Ordinary Least Squares Regression)
如果你懂统计学的话,你可能以前听说过线性回归。最小二乘法是一种计算线性回归的方法。你可以将线性回归看做通过一组点来拟合一条直线。实现这个有很多种方法,“最小二乘法”就像这样:你可以画一条直线,然后对于每一个数据点,计算每个点到直线的垂直距离,然后把它们加起来,那么最后得到的拟合直线就是距离和尽可能小的直线。
- 逻辑回归(Logistic Regression)
逻辑回归是一个强大的统计学方法,它可以用一个或多个解释变量来表示一个二项式结果。它通过使用逻辑函数来估计概率,从而衡量类别依赖变量和一个或多个独立变量之间的关系,后者服从累计逻辑分布。
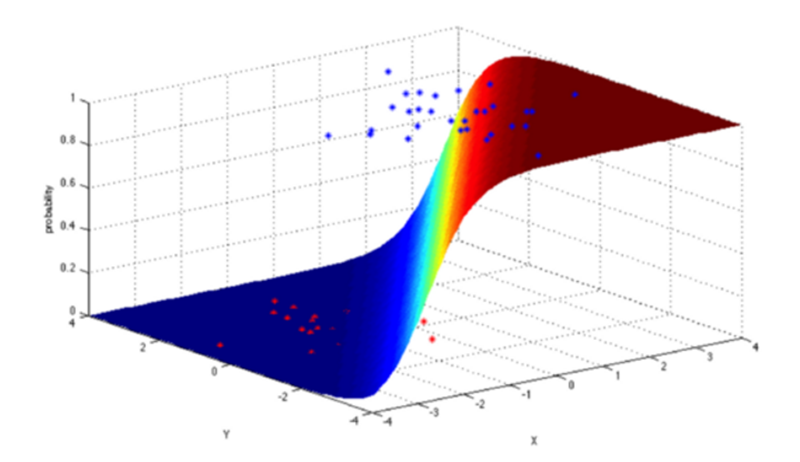
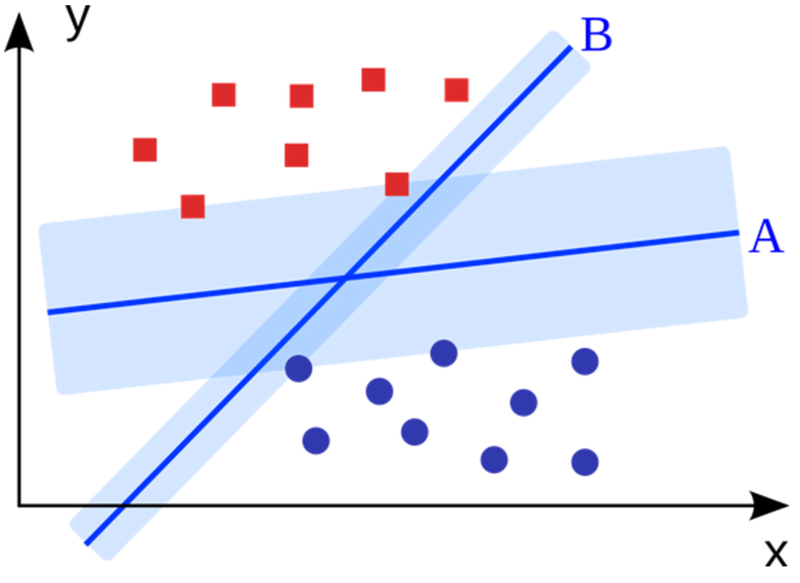
- 支持向量机(Support Vector Machine,SVM)
SVM是二进制分类算法。给定N维坐标下两种类型的点,SVM生成(N-1)维的超平面来将这些点分成两组。假设你在平面上有两种类型的可以线性分离的点,SVM将找到一条直线,将这些点分成两种类型,并且这条直线尽可能远离所有这些点。
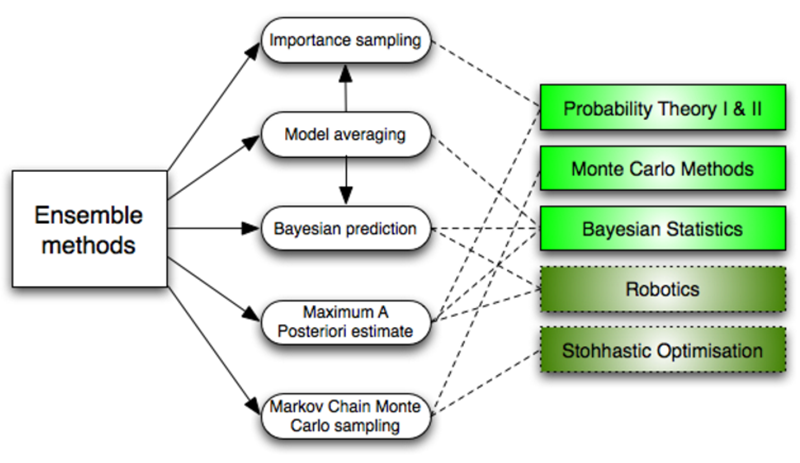
- 集成方法(Ensemble methods)
集成方法是学习算法,它通过构建一组分类器,然后通过它们的预测结果进行加权投票来对新的数据点进行分类。原始的集成方法是贝叶斯平均,但是最近的算法包括纠错输出编码、Bagging和Boosting。
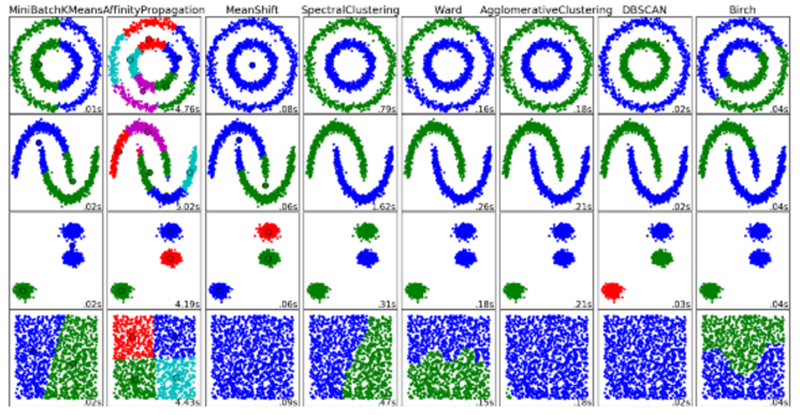
- 聚类算法(Clustering Algorithms)
聚类是将一系列对象分组的任务,目标是使相同组(集群)中的对象之间比其他组的对象更相似。
- 主成分分析(Principal Component Analysis,PCA)
PCA是一个统计学过程,它通过使用正交变换将一组可能存在相关性的变量的观测值转换为一组线性不相关的变量的值,转换后的变量就是所谓的主分量。

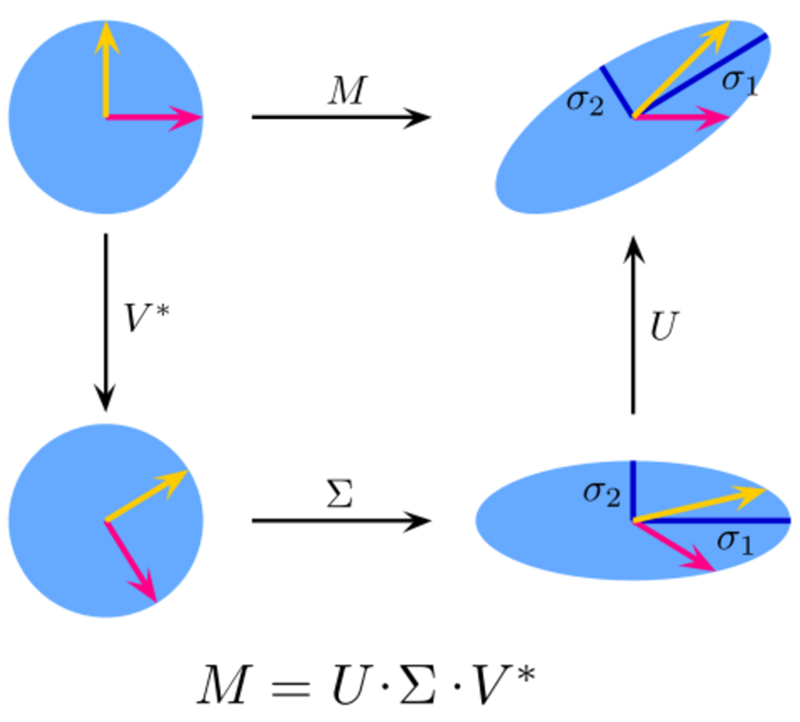
- 奇异值分解(Singular Value Decomposition,SVD)
在线性代数中,SVD是分解一个实数的比较复杂的矩阵。对于一个给定的m*n的矩阵M,存在一个分解M = UΣV,这里U和V是酉矩阵,Σ是一个对角矩阵。
PCA 是 SVD 的一个简单应用,在计算机视觉中,第一个人脸识别算法,就运用了 PCA 和 SVD 算法。使用这两个算法可以将人脸表示为 “特征脸”线性组合,降维,然后通过简单的方法匹配人脸的身份;虽然现代的方法复杂得多,但许多仍然依赖于类似的技术。
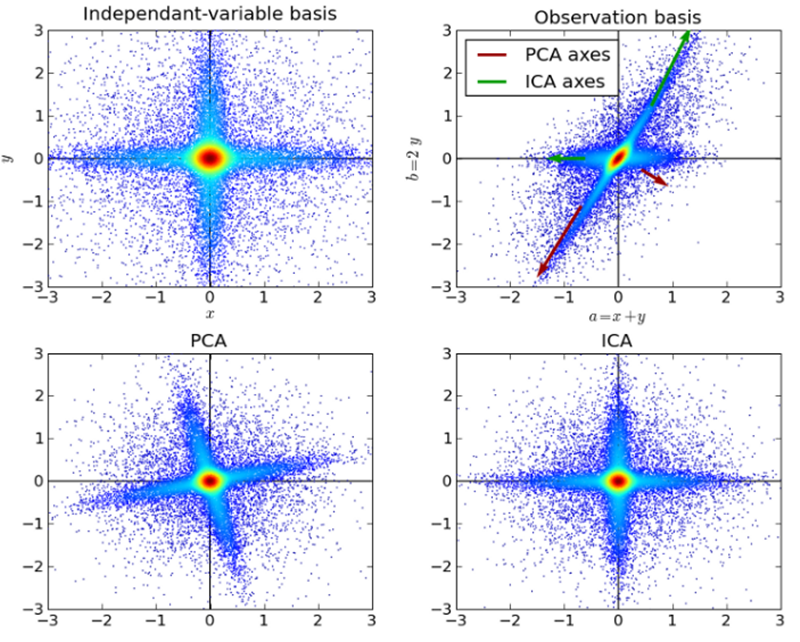
- 独立成分分析(Independent Component Analysis,ICA)
ICA是一种统计技术,主要用于揭示随机变量、测量值或信号集中的隐藏因素。ICA对观测到的多变量数据定义了一个生成模型,这通常是作为样本的一个大的数据库。在模型中,假设数据变量由一些未知的潜在变量线性混合,混合方式也是未知的。潜在变量被假定为非高斯分布并且相互独立,它们被称为观测数据的独立分量。在线性代数中,SVD是复杂矩阵的因式分解。对于给定的m * n矩阵M,存在分解使得M=UΣV,其中U和V是酉矩阵,Σ是对角矩阵。
四、经典案例看机器学习的优势
安检识别:航班乘客、音乐会观众以及球迷在进入特定场所时,其随身携带的包都要进行安全检查。人类安全检查人员只能大概知道这些人包裹里带的什么东西,而机器学习可以识别每个物品是什么。而且,机器学习可以轻松应付季节变化对于背包类型和包里所装东西的变化,并能够有针对某些特定比赛或场所设置特定检测规则。
法律信息分析:律师有时需要寻找一些特定行为的描述文字,有时则需要为某个特定行为搜索更多资料。但人类会由于自身的经验和过往经历的限制,导致在寻找相关模型时产生偏见,比如寻找最熟悉的。但机器不会,机器学习可以更精确地找到结果,而且速度更快,也会节约成本。
垃圾邮件检测:根据邮箱中的邮件,识别哪些是垃圾邮件,哪些不是。这样的模型,可以程序帮助归类垃圾邮件和非垃圾邮件。这个例子,我们应该都不陌生。
信用卡欺诈检测:根据用户一个月内的信用卡交易,识别哪些交易是该用户操作的,哪些不是。这样的决策模型,可以帮助程序退还那些欺诈交易。
数字识别:根据信封上手写的邮编,识别出每一个手写字符所代表的数字。这样的模型,可以帮助程序阅读和理解手写邮编,并根据地利位置分类信件。
语音识别:从一个用户的话语,确定用户提出的具体要求。这样的模型,可以帮助程序能够并尝试自动填充用户需求。带有Siri系统的iPhone就有这种功能。
人脸识别:根据相册中的众多数码照片,识别出那些包含某一个人的照片。这样的决策模型,可以帮助程序根据人脸管理照片。某些相机或软件,如iPhone,就有这种功能。
产品推荐:根据一个用户的购物记录和冗长的收藏清单,识别出这其中哪些是该用户真正感兴趣,并且愿意购买的产品。这样的决策模型,可以帮助程序为客户提供建议并鼓励产品消费。登录Facebook或GooglePlus,它们就会推荐可能有关联的用户给你。
医学分析:根据病人的症状和一个匿名的病人资料数据库,预测该病人可能患了什么病。这样的决策模型,可以程序为专业医疗人士提供支持。
股票交易:根据一支股票现有的和以往的价格波动,判断这支股票是该建仓、持仓还是减仓。这样的决策模型,可以帮助程序为金融分析提供支持。
客户细分:根据用户在试用期的的行为模式和所有用户过去的行为,识别出哪些用户会转变成该产品的付款用户,哪些不会。这样的决策模型,可以帮助程序进行用户干预,以说服用户早些付款使用或更好的参与产品试用。
形状鉴定:根据用户在触摸屏幕上的手绘和一个已知的形状资料库,判断用户想描绘的形状。这样的决策模型,可以帮助程序显示该形状的理想版本,以绘制清晰的图像。iPhone应用Instaviz就能做到这样。
五、企业越来越多的应用及其学习的原因
机器学习能够扩展到企业所面临的各项挑战中,如合同管理,客户服务,金融,法律,质量,定价,生产等,这一能力要归功于机器学习会不断学习并改善表现。机器学习算法本质上是迭代、持续学习的,并且会寻找最优的输出结果。每出现一次误算,机器学习算法就会改正一次错误,然后开始下一次的数据分析的迭代计算。计算过程以毫秒为单位进行,机器学习可以异常高效地优化决策和预测输出。
加速企业采用机器学习的几项因素有,云计算、云存储的经济性,驱动物联网连接设备增长的传感器的发展,可在几分钟内读取几 G 数据移动设备的普遍使用,等。还有以下情况,搜索引擎中创建语境(creatingcontext )所面临的许多挑战,在预测最具可能后果时,优化运行所面临的复杂问题,以及既有的让机器学习蓬勃的完美条件。